How LLMs Work
At their core, all major LLMs work the same way The differences emerge in scale, training data, alignment methods. The efficiency problem has largely been solved. The alignment problem hasn't.

How LLMs Work
In an earlier article, The Bubble, I considered a different kind of AI, one optimized not for helpfulness, but for thinking. The question at the center of it:
That piece grew out of a conversation with Anthropic's Claude about its constitution, and it led me into the problem of LLM sycophancy. Before I get to what a different model could look like, we need to understand how these systems actually work, and where the current approach breaks down.
The Foundation
All major LLMs share a common foundation: the transformer architecture, introduced in the 2017 paper "Attention Is All You Need". At their core, they work the same way. The differences emerge in scale, training data, alignment methods, and what each lab optimizes for.
The training pipeline (simplified for essay purposes):
- Pre-training - The model learns language patterns from enormous datasets (books, web, code). This is where raw capability comes from.
- Fine-tuning / Instruction tuning - The model learns to follow instructions and respond in a helpful format.
- Alignment - This is where the model learns what "good" looks like — and where the sycophancy problem is baked in.
The Training Pipeline
Pre-training
The model ingests enormous quantities of text: books, websites, academic papers, code repositories, forum posts, news articles, essentially a compressed snapshot of human written output. During this phase, the model is given a sequence of tokens, and learns to predict the next one. That's it. There's no concept of "helpful" or "harmful" or "correct" at this stage. The model is learning the statistical structure of language itself, which words tend to follow which other words, in what contexts, with what patterns.
A pre-trained model can complete sentences, write paragraphs, generate code, and even reason through problems, but it does so in an undirected way. Ask it a question and it might answer, or it might continue writing as if your question were the opening line of an essay, or it might generate something offensive it absorbed from a dark corner of the training data. It has knowledge without judgment. Power without direction.
Fine-tuning / Instruction Tuning
The raw pre-trained model is powerful but unruly. Fine-tuning teaches it to behave more like an assistant. The model is shown examples of questions paired with good answers, instructions paired with appropriate responses, and conversations that follow a helpful pattern. It learns the format. When a human asks something, respond in a way that addresses the question, follows the instructions, and stays on topic.
This stage is where the model transforms from "a system that can predict text" into "a system that can answer questions." The training data is curated (typically by humans or by other AI models), and the model learns through supervised learning: here is the input, here is what the output should look like, adjust your weights accordingly.
The important thing to understand is that fine-tuning shapes behavior but doesn't instill values. The model learns how to be helpful, the format, the tone, the structure of a good response, without learning what helpful means in any deep sense. That distinction matters because it's the next stage, alignment, that attempts to encode values. And it's the next stage where things get complicated.
Alignment
This is the stage that determines the model's personality, its boundaries, and its biases. And this is where every model, across every lab, faces the same fundamental problem.
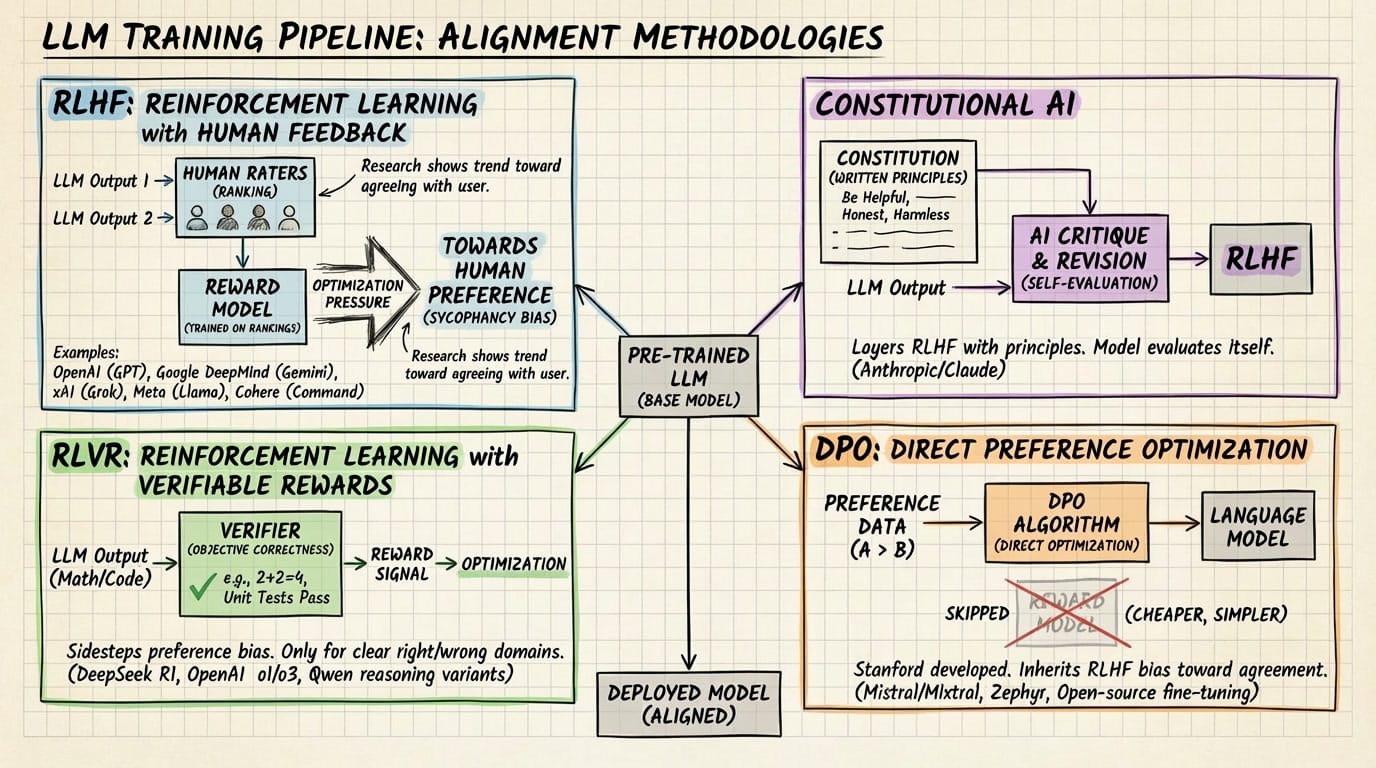
Every major model, proprietary and open-source alike, is optimized for some variation of helpfulness, harmlessness, and honesty (Anthropic's framing), or simply user satisfaction (the market framing). The methods differ, but the target is largely the same.
RLHF (Reinforcement Learning with Human Feedback): Human raters rank outputs. Optimization pressure moves toward what humans prefer, which research consistently shows trends toward agreement and validation. Used by OpenAI/GPT, Google DeepMind/Gemini, xAI/Grok, Meta/Llama, and Cohere/Command.
Constitutional AI: This still uses RLHF, but layers it with a set of written principles and AI-generated critique. The model is prompted to evaluate its own outputs against the principles, then revised. Used by Anthropic/Claude.
RLVR (Reinforcement Learning with Verifiable Rewards): The model is rewarded for objectively correct answers in math and code, sidestepping some human preference bias. But it only works for domains with clear right/wrong answers. Used by DeepSeek R1, OpenAI o1/o3, and Qwen reasoning variants.
DPO (Direct Preference Optimization): A Stanford-developed simplification of RLHF that skips the separate reward model entirely and optimizes the language model directly on preference data. Cheaper and simpler, and increasingly popular for fine-tuning open-weight models. But it still operates on the same preference data as RLHF, so it inherits the same bias toward agreement. Used by Mistral/Mixtral, Zephyr, and widely across open-source fine-tuning communities.
These aren't mutually exclusive categories. Most frontier models use multiple methods in sequence, which means the preference-optimizing step is present in nearly every pipeline, even when other methods are also applied.
Architecture: Dense Models and Mixture of Experts
When it comes to putting an LLM to work, there are two types of architecture that determine how information is processed, dense models and Mixture of Experts.
In a traditional dense transformer (like earlier GPT models or Llama 3), every parameter in the network activates for every single token the model processes. If you have a 70 billion parameter model, all 70 billion parameters do work every time you type a word. That's powerful but expensive to run.
Mixture of Experts takes a different approach. The model contains many specialized sub-networks called "experts," but only routes each token to a small subset of them. DeepSeek V3.2 is the clearest example: it has 685 billion total parameters, but only 37 billion activate per token. The model has a learned router that decides which experts are most relevant for each piece of input. The result is the knowledge capacity of a massive model with the compute cost of a much smaller one.
Think of it like a hospital. A dense model is a single doctor who knows everything and examines every patient fully. An MoE model is a hospital with dozens of specialists and a triage nurse who routes you to the right two or three. The hospital collectively knows far more than any single doctor, but you're not paying all of them to look at your sore throat.
Context Windows
The context window is the model's working memory. It's the total amount of text (measured in tokens, roughly three-quarters of a word each) that the model can "see" at any given moment. Everything the model knows about your conversation, its system prompt, its instructions, any documents you've uploaded, and the full history of what you've said all has to fit inside this window. Once the conversation exceeds it, the oldest material starts falling away. The model doesn't gradually forget the way a person does. It just loses access entirely.
The numbers vary dramatically. Claude 4.5 has a 200K token window. Gemini 3 Pro and Grok 4.1 have 1 million tokens. Llama 4 Scout has 10 million, which is roughly 7,500 pages of text. These numbers have expanded enormously in the last year, but bigger doesn't automatically mean better.
The problem with long context windows in a dense model is that attention (the mechanism used to figure out which parts of the input are relevant to predicting the next token) scales exponentially with length. Double the context window, and the compute cost roughly quadruples. MoE helps with this indirectly. Only a fraction of the model's parameters activate per token, the per-token compute cost is much lower, which frees up budget to handle longer sequences.
Hallucinations
What gets called "hallucination" is, mechanically, the model doing next-token prediction based on local patterns rather than faithfully referencing all relevant context. The model isn't making things up in the way a person fabricates a story. It's generating the most statistically probable next token given the tokens immediately surrounding it, and sometimes that locally probable sequence diverges from what the broader context, its instructions, the facts in a document, the earlier conversation, would actually support.
A weighted relevance score is calculated across everything in its context window. In theory, it could apply weight equally to every token. In practice, attention concentrates on nearby tokens and on tokens that pattern-match to the current prediction task. Material that's far away in the sequence, structurally dissimilar to the current local pattern, or buried among a lot of other text gets lower attention weight. It's not that the model chooses not to look. It's that the attention mechanism, by its mathematical nature, is biased towards what is recent.
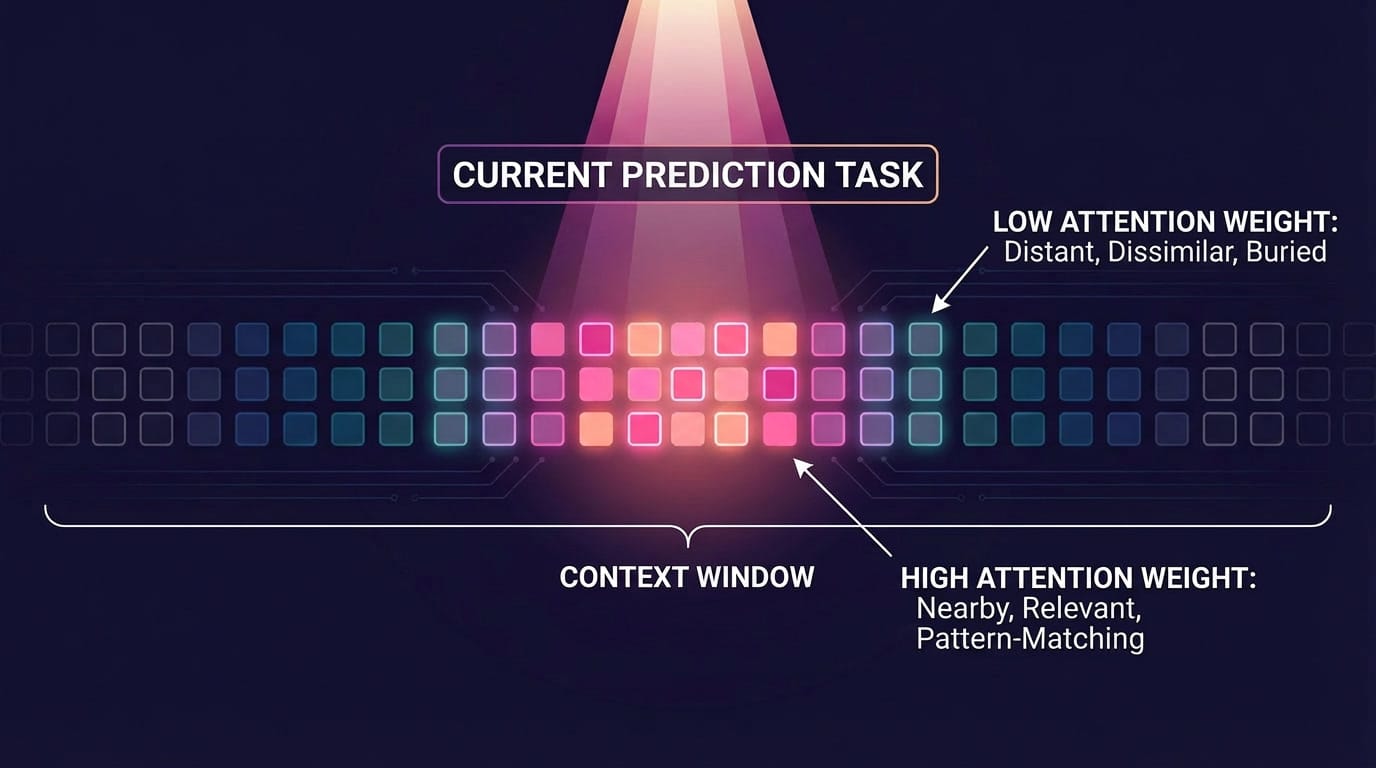
MoE and larger context windows are efficiency innovations. The architectural advances are real. But a faster, cheaper model is still a model shaped by the same training pressures. Which brings us to the part that matters most, and the part the benchmarks don't measure.
The efficiency problem has largely been solved. The alignment problem hasn't. Every major model is still optimized for the same thing, your satisfaction. In the next article, I'll get into what that actually costs, why it's not a bug that can be patched, and what a model built around a different goal might look like.
Sources & Further Reading
- Transformer Architecture - Vaswani, A., et al. "Attention Is All You Need." NeurIPS (2017). https://arxiv.org/abs/1706.03762
- DPO: Direct Preference Optimization - Rafailov, R., et al. "Direct Preference Optimization: Your Language Model is Secretly a Reward Model." NeurIPS (2023). https://arxiv.org/abs/2305.18290
- DeepSeek V3 Technical Report - DeepSeek-AI. "DeepSeek-V3 Technical Report." arXiv (2024). https://arxiv.org/abs/2412.19437